🔊 Voice / TTS Architecture
Four-tier text-to-speech fallback chain. Best-quality cloud voices when online; bundled neural models when not. Used by Prism AAC, in-call notifications, accessibility narration, and any app feature that speaks.🎚️ Four-Tier Fallback Chain
| Tier | Engine | Quality | Offline | Cost | When |
|---|---|---|---|---|---|
| 1 | Deepgram Aura (cloud) | Best-in-class — natural prosody, 60+ voices, voice cloning | — | Per-character billing; free for ro/uk/ru/de/ko/ar (Synalux absorbs cost) | Default for paid tiers; default for free tier in subsidized languages |
| 1.5 | Kokoro-82M neural (WASM) | Very good — locally-run neural voice | ✅ en/es/fr/pt/ja/zh | $0 | Free tier non-subsidized langs; offline; Tier 1 unavailable |
| 2 | OS Web Speech API premium voices | Good — varies by OS (Apple voices best) | ✅ | $0 | Tier 1.5 unavailable in user's language; bandwidth-saver mode |
| 3 | WASM espeak-ng | Acceptable — robotic but always works | ✅ | $0 | Last resort; covers 100+ languages |
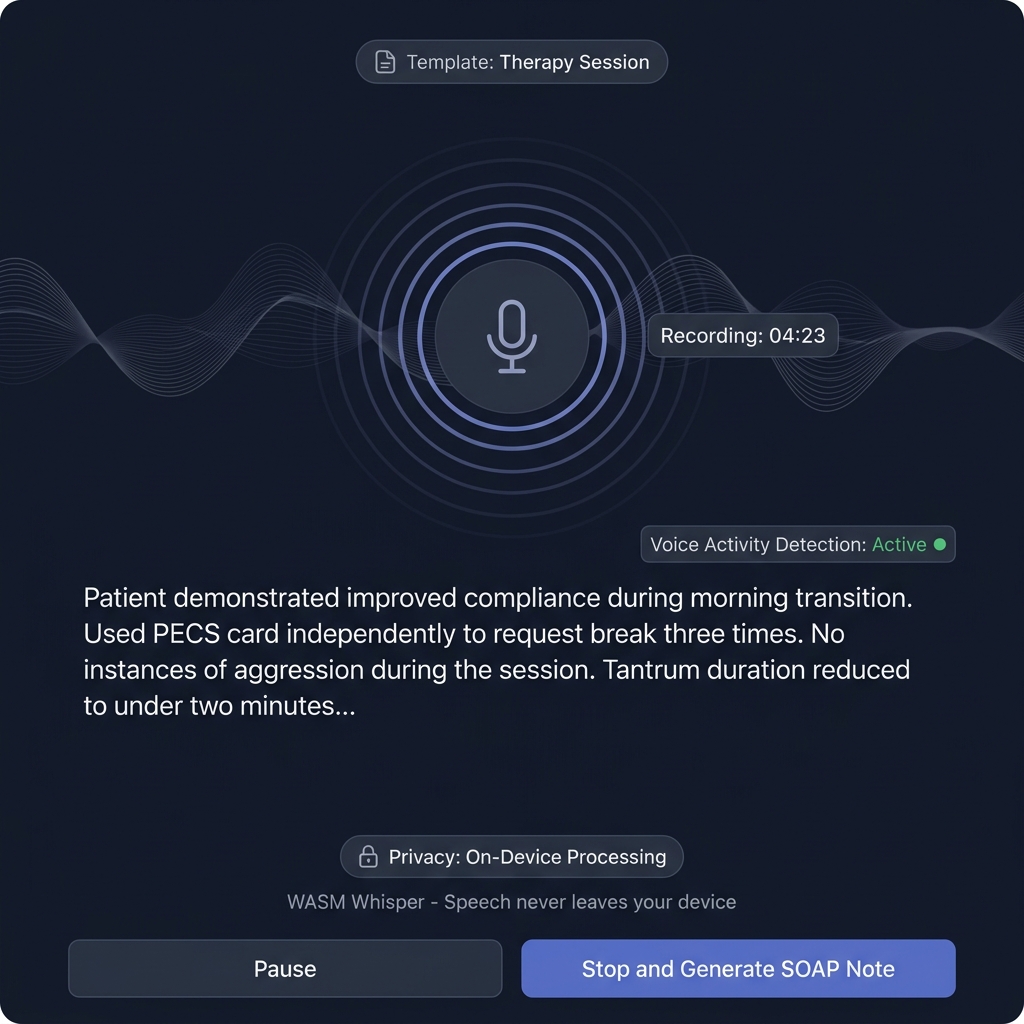
The chain is automatic — no user configuration required. The voice picker (paid) lets users override their default with any Tier 1 voice.
🎤 Voice Cloning (Paid)
"Speak in MY voice — I trained it last week."
* 3-minute training sample uploaded once via the Voice Picker UI.
* Deepgram voice-clone training takes ~10 minutes; the cloned voice is then available alongside the standard 60+ voices.
* Workspace-scoped — clones are bound to the workspace; staff voices auto-shared, patient voices private.
* Use cases: AAC users speak in a parent's voice; clinicians who prefer to hear notes in their own voice; demo videos for parents/caregivers.
🌍 Subsidized Languages (Free Tier)
Synalux absorbs Deepgram Aura cost for these languages on the free tier so users in regions where the platform serves underserved populations get premium voices at no cost:
ro (Romanian) · uk (Ukrainian) · ru (Russian) · de (German) · ko (Korean) · ar (Arabic)
🩺 Why This Matters Clinically
* Children with speech impairments depend on AAC's TTS for their actual voice — robotic Tier-3 fallbacks aren't acceptable for daily use; Tier 1 / 1.5 must succeed.
* Bilingual households need accurate prosody in both languages — Tier 1 is critical for non-English.
* Offline reliability — a child at school without Wi-Fi must still have their device speak. Tier 1.5 + 2 + 3 are bundled; the device always talks.
🏗️ Architecture
``
POST /api/v1/tts Generate TTS audio (auto tier-route based on lang + tier + connectivity)
POST /api/v1/tts/public Anonymous TTS for AAC widgets (rate-limited per IP)
GET /api/v1/tts/voices List available voices for the user's tier + language
POST /api/v1/voices/clone Submit a voice-clone training sample (paid)
`
Routing logic:
`
synthesize(text, lang, voice?) →
if voice && Tier1.available(voice): return Tier1.speak(text, voice)
if Tier1.available(lang) && (paid || Tier1.subsidizes(lang)): return Tier1.speak(text)
if Tier1_5.supports(lang): return Tier1_5.speak(text) // Kokoro
if Tier2.has(lang): return Tier2.speak(text) // Web Speech API
return Tier3.speak(text) // espeak-ng
``
💳 Plans
| Free | Standard | Advanced | Enterprise | |
|---|---|---|---|---|
| Default Deepgram voice | ✅ | ✅ | ✅ | ✅ |
| All 60+ Deepgram voices | — | ✅ | ✅ | ✅ |
| Voice cloning | — | — | ✅ | ✅ |
| In-call clinical dictation TTS feedback | — | ✅ | ✅ | ✅ |
| Custom voice library (workspace-curated) | — | — | — | ✅ |
🔄 Where TTS Is Used
* Prism AAC — picture tiles → speech, keyboard speak button, math panel AI tutor.
* In-call notifications — meeting started, patient joined, recording started.
* Accessibility narration — for users with low vision; reads notifications + form errors.
* AAC chat — assistant responses can be auto-spoken with the user's selected voice.